Yes, we can as well :)
In the past it was often confusing to users that we have two source repositories for RHQ and Jopr. We have recently changed this.
The new RHQ repository lives now at http://git.fedorahosted.org/. There are a few branches defined, but the main one of interest is origin/master.
As you can see, we have not only move the repository location, but also move to the git version control system and even merged Jopr and RHQ together into one repository - so no more riddling where to find what.
See also this post about the change to bug tracking.
Monday, October 26, 2009
RHQ Bugtracker moves to Bugzilla - action required
Project RHQ, which is the foundation for Jopr will soon move all bug tracking from the old JIRA system at jira.rhq-project.org over to a bugzilla instance at Red Hat.
So when you have an account at the jira and reported bugs, you should follow those steps to have your cases linked to you on the new bugzilla site:
- Go to bugzilla at bugzilla.redhat.com
- If you don't yet have an account create one with your preferred email address.
- If you do have an account, login (or submit a password change request then login). And make a note of the email address you are using.
- If you don't yet have an account create one with your preferred email address.
- Go to RHQ jira (http://jira.rhq-project.org/browse/RHQ),
log in and set your email address through your profile (http://jira.rhq-project.org/secure/EditProfile!default.jspa) to the one you are using in bugzilla above.
Cutover will happen within the next few days
For now, the Jopr bugtracker will stay at the JBoss jira, but will probably also merged into bugzilla in the future.
Tuesday, October 13, 2009
Embedding ruby in java - less than trivial so far
Currently I am trying to get puppet, a configuration management system to be executed in Jruby - and especially embedded within some java code.
Luckily there is the JSR 223 scripting available in Java6, so the start is relatively easy: get jruby from jruby.org and add it to the java programs classpath, java program code looks like this:
Simple - eh?
Unfortunately is it not that simple (yet).
Passing the argument vector to my script does not yet work in jruby 1.4 cr1 (see JRUBY-4090), so I need to do a work around of defining a script, that sets this and then calls puppet
Next, puppet is complaining about missing stuff like OpenSSL (which is a difficult beast in jruby, as the standard ruby implementation needs some C code, which can not directly run in jruby).
Also it is somehow complaining about yecht not being found - I still don't really grok setting and properties up things like jruby.lib, jruby.home etc.
If anyone can shed some light on it, I would appreciate it :-)
Luckily there is the JSR 223 scripting available in Java6, so the start is relatively easy: get jruby from jruby.org and add it to the java programs classpath, java program code looks like this:
// Define path to jruby libraries
System.setProperty("jruby.home","/opt/local/share/java/jruby");
// Get the scripting engine
ScriptEngineManager m = new ScriptEngineManager();
ScriptEngine rubyEngine = m.getEngineByName("jruby");
// Define the puppet script to run as arguments
rubyEngine.put(ScriptEngine.ARGV,new String[]{"example.pp"});
// read the script
File f = new File("puppet.rb");
BufferedReader br = new BufferedReader(new FileReader(f));
// and execute it
rubyEngine.eval(br, context);
Simple - eh?
Unfortunately is it not that simple (yet).
Passing the argument vector to my script does not yet work in jruby 1.4 cr1 (see JRUBY-4090), so I need to do a work around of defining a script, that sets this and then calls puppet
ARGV << 'example.pp'
require 'puppet/application/puppet'
Puppet::Application[:puppet].run
Next, puppet is complaining about missing stuff like OpenSSL (which is a difficult beast in jruby, as the standard ruby implementation needs some C code, which can not directly run in jruby).
Also it is somehow complaining about yecht not being found - I still don't really grok setting and properties up things like jruby.lib, jruby.home etc.
If anyone can shed some light on it, I would appreciate it :-)
Wednesday, October 07, 2009
Jopr, RHQ and the availability check interval (updated)
Jopr and RHQ check from time to time for each resources availability. This is done in the agent, where a periodic thread calls the
getAvailability() method of each ResourceComponent. After this scan the result is sent to the server and the server shows the red and green state on the resource.This server side processing creates a certain stress in large environements (say: hundreds of agents with ten thousands of resources), so that in Jopr 2.3 we have increased the interval this check is done to 5 minutes.
For many use cases (smaller installs, testing) this is too long. Luckily, this interval is not cast in stone, but configurable in the agent settings file,
conf/agent-configuration.xml:
<!--
_______________________________________________________________
rhq.agent.plugins.availability-scan.period-secs
Defines how often an availability scan is run. This type
of scan is used to determine what resources are up and running
and what resources have gone down. The value is specified in
seconds.
-->
<!--
<entry key="rhq.agent.plugins.availability-scan.period-secs" value="300"/>
-->
You see the default is shown as commented value. To change this to a different value, remove the xml comment signs around it and change this back to e.g. 60 seconds (it will probably not make any sense to go lower than that, as the load on the agent, your managed resource and also the Jopr server will increase again):
<!--
-->
<entry key="rhq.agent.plugins.availability-scan.period-secs" value="60"/>
After this is done, you need to restart the agent to have it read the new value (see also next paragraph).
UPDATE
As the agent writes its configuration into the java preferences as backing store, the above change will not directly be honored. This may sound strange at first, but it has the advantage that you can run an agent, remove it, install a newer version of it and have the new version automatically use the saved values of the first agent install.
So you need to tell the agent that it indeed should read the new configuration file. This can be done by starting the agent with the option
--clenanconfig or better by supplying -c agent-configuration.xml. This is explained at the top of the agent-configuration.xml file and also in the yellow box in the agent install document.Of course this applies to JBoss ON 2.3 as well.
Monday, October 05, 2009
Jopr installer bug - careful when testing
The RHQ 1.3 and Jopr 2.3.1 installer has a little issue (see RHQ-2222 jira), where it clears out the database password when you click on "Test connection".
Lets have a look at a screen shot:
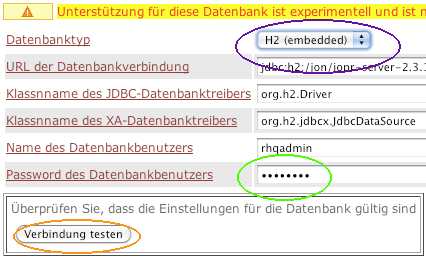
When setting a database password (green circle) and then testing the connection (orange circle), the password will be reset and the install will fail later on.
If you are using the embedded H2 database, just re-select it in the drop down (violet circle) to have the database password filled in again by the system. Actually with H2, there is no need to test the connection in the first place :-)
Friday, October 02, 2009
RHQ tip of the day: agent confused?
Darko asked the other day on the Jopr Irc channel:
I have an agent, which isn't collecting my cpu-load data any more. I also have many more problems with the agent. How can I reset the agent to collect all data again? It may have to do with the fact that I had a server crash on the system with the running agent. Since the crash the agent isn't working any more.
It looks like the internal state database of the agent got confused. When the agent is fully configured and working, it will save its inventory of locally managed resources (a part of the global inventory kept on the server) along with their measurement schedules in a local database.
The agent can use this database to start working on the next start even if the server is not reachable. Changes on the server will synchronized when the connection is up again.
Now back to the original question: To get the agent going again, you need to erase the bad inventory and sync with the server again. You can do this by passing option
To see a full list of the agents command line options, you can pass the
I have an agent, which isn't collecting my cpu-load data any more. I also have many more problems with the agent. How can I reset the agent to collect all data again? It may have to do with the fact that I had a server crash on the system with the running agent. Since the crash the agent isn't working any more.
It looks like the internal state database of the agent got confused. When the agent is fully configured and working, it will save its inventory of locally managed resources (a part of the global inventory kept on the server) along with their measurement schedules in a local database.
The agent can use this database to start working on the next start even if the server is not reachable. Changes on the server will synchronized when the connection is up again.
Now back to the original question: To get the agent going again, you need to erase the bad inventory and sync with the server again. You can do this by passing option
--purgedata to the agent commandline:$ bin/rhq-agent.sh --purgedataTo see a full list of the agents command line options, you can pass the
--help option to the agent start script.
Thursday, October 01, 2009
RHQ tip of the day: Help, my resource does not show in the tree!
We see it from time to time that people have correctly set up Jopr or RHQ and want to monitor e.g. a JBoss AS server or other resources. They even have an agent running on the machine with the JBoss AS on, but still it does not show up in the resource tree of this platform.
Most often this is a simple issue, as the resource is just sitting in the queue to be imported into inventory:
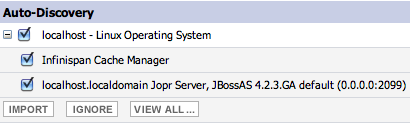
Just select the ones you want to import, click on the import button and after a second, the resource will show up in the resource tree below its platform.
Jopr and RHQ require this on purpose, as this way you can ignore e.g. servers that are just up at the moment of import, but which are not to be managed.
As you have seen that resources can be ignored, there is also a way to "bring them back" when you decide later to import them. Either click on "View all..." in the Auto-Discovery portlet seen above or select Auto discovery queue from the Overview menu, then select Both new and Ignored from the drop-down:
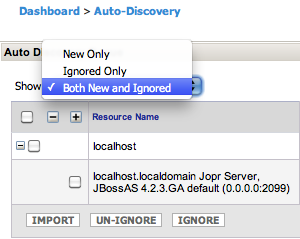
This will show ignored resources, that you can check and then click un-ignore to get them back into the new state from where you can finally import them.
Subscribe to:
Posts (Atom)